Iterative Machine Learning: A step towards Model Accuracy
原文标题:Iterative Machine Learning: A step towards Model Accuracy
原文作者:Amarabha Benerjee
通过死记硬背来学习一些东西,比如重复多次,通过一遍又一遍地练习来完善一项技能,或者通过逐步对原型进行细微调整来构建某些东西,这些都是我们人类自然而然发生的事情。机器也可以学习这种方式,这被称为“迭代机器学习”。在大多数情况下,迭代是一种有效的学习方法,有助于更快、更准确地达到预期的最终结果,而不会成为资源紧缩的噩梦。
现在,你可能会想,迭代本身不就是任何机器学习的一部分吗?换句话说,从基础的回归分析、决策树、贝叶斯网络到高级的神经网络和深度学习算法,现代机器学习技术都内置了一些固有的迭代组件。那么,将迭代学习作为一个独立的主题来讨论的必要性是什么呢?这仅仅是因为将迭代外部引入到算法可以最大限度地减少误差范围,从而有助于准确建模。
迭代学习是如何工作的
让我们仔细观察机器学习算法中单个迭代流期间发生的情况来了解迭代的原理。
首先将预处理的训练数据集引入到模型中。在对给定的数据进行处理和构建模型后,对模型进行测试,然后将结果与所期待的输出进行匹配。然后将反馈返回给系统,以便算法那进一步学习和微调其结果。这清楚地表明,这里发生了两个迭代过程:
- 数据迭代——算法固有的
- 模型训练迭代——外部引入
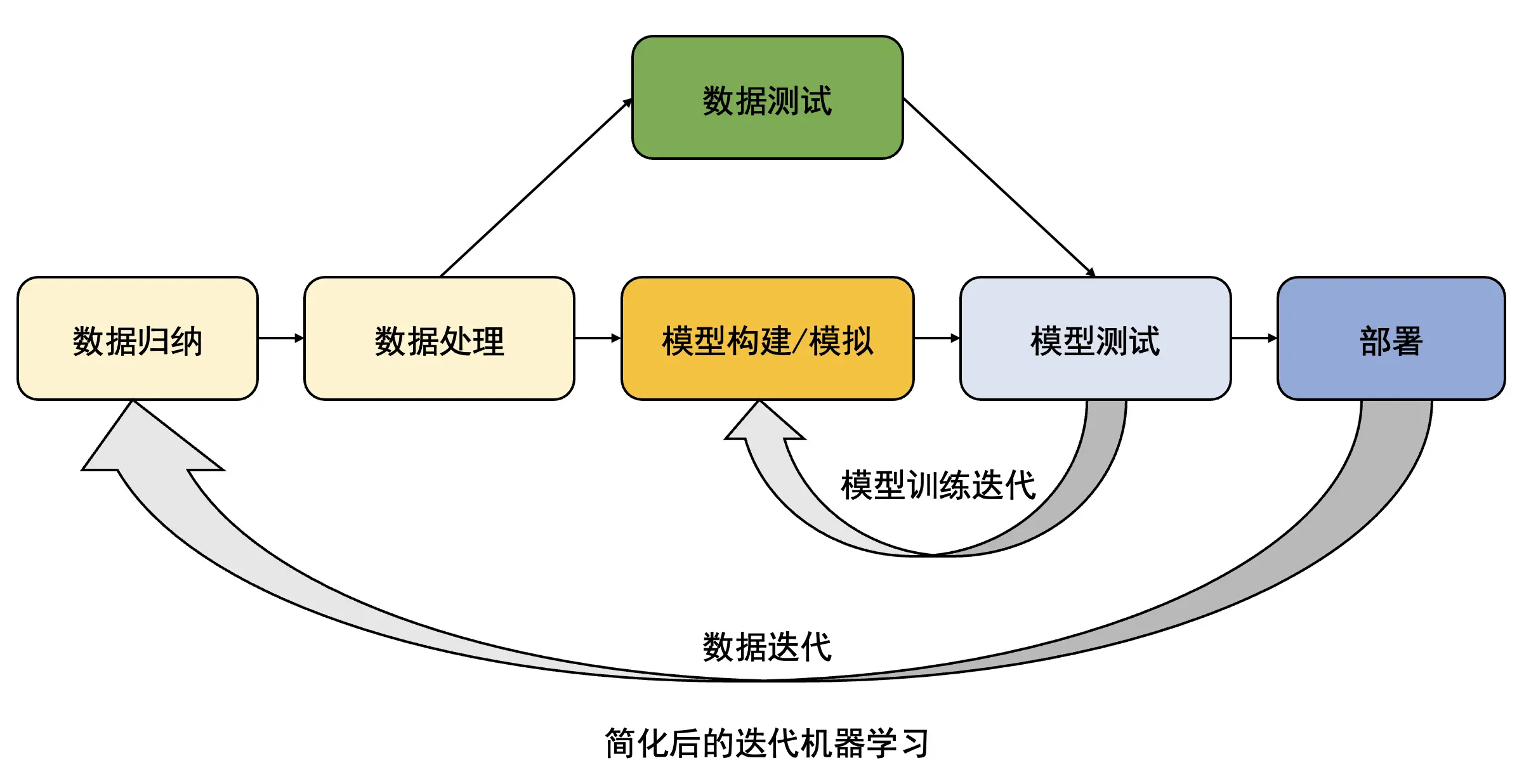
现在,如果我们没有将结果反馈到系统中,比如说不允许算法迭代学习,而是采用顺序方法,情况会变成怎么呢?算法是否有效,能否提供正确的结果呢?
是的,算法肯定会起作用。但是,它产生的结果的质量将会因为许多因素而有很大的差异。训练数据集的质量和数量、所采用的特征定义和特征抽取技术、算法本身的鲁棒性等都是许多因素之一。即使上述所有工作都做得完美,仍然不能保证顺序方法产生的结果将非常准确。简而言之,结果既不准确,也不可重复。因此,迭代学习允许算法提高模型准确性。
某些算法在设计中具有迭代核心,可以根据数据量的多少进行缩放。这些算法处于机器学习实现的最前沿,因为它们能够更快更好地执行。在接下来的部分,我们将讨论来自三种主要机器学习方法的不同算法类别的迭代——有监督机器学习、无监督机器学习和强化学习。
提升算法:有监督机器学习中的迭代
提升算法本质上是迭代的,是通过最小化错误来改善结果的最佳方式。它们主要旨在减少结果中的偏差,并将一组特定的弱学习分类器算法转换为强学习器,从而使它们能够减少错误。以下是一些示例:
- AdaBoost(Adaptive Boosting)
- 梯度提升树(Gradient Tree Boosting)
- XGBoost
它们是如何工作的
所有的提升算法都有一个通用的分类器,这些分类器经过迭代修改以达到想要的结果。让我们以“在某篇文章中找抄袭案例”为例。这里的第一个分类器是找到一组单词,这些单词出现在其他地方或者另一篇文章中,这将导致一个红色信号。如果我们创建 10 个单独的单词组,并将它们称为分类器 1 到 10,那么我们将根据这些分类器检查我们的文章,并且任何可能的匹配都将会标记为红色。但是,这 10 个分类器没有任何红色信号并不意味着一个肯定的 100% 原创文章。因此,我们需要更新分类器,创建可能基于第一次通过的更短的组,从而提高分类器发现这篇文章与其他文章的相似性的准确性。Boosting 算法中的这个迭代过程最终使我们获得了相当高的准确率。原因是在每次迭代之后,分类器都会根据其性能进行更新。与其他内容非常相似的内容将进行更新和调整,以便我们可以获得更好的匹配。这种本质上改进算法的过程被称为提升,目前是有监督机器学习中最流行的方法之一。
优缺点
这种方法的明显优点是,它允许在最终模型中出现最小的错误,因为迭代模型能够在每次出现错误时自行纠正。缺点是处理时间较长,并且大量迭代对总体内存的要求较高。另一个重要方面是,反馈给训练模型的错误是在外部完成的,这意味着监督者可以控制模型及其修改方式。这反过来又有一个缺点,即模型无法学会自行消除错误。因此,该模型不能用于另一组数据。换句话说,模型不会自己学习如何变得无差错,因此不能移植到另一个数据集上,因为它需要从头开始学习过程。
人工神经网络:无监督机器学习中的迭代
神经网络已经成为无监督机器学习的典型代表,因为它们在预测数据模型方面的准确性。一些众所周知的神经网络有:
- 卷积神经网络(Convolutional Neural Networks,CNNs)
- 玻尔兹曼机(Boltzman Machines,BMs)
- 循环神经网络(Recurrent Neural Networks,RNNs)
- 深度神经网络(Deep Neural Networks,DNNs)
- 记忆网络(Memory Networks,MNs)
它们是如何工作的
人工神经网络在模拟数据模型方面非常准确,主要是因为它们的迭代学习过程。但这个过程与我们之前探索的 Boosting 算法的过程不同。在这里,这个过程是无缝和自然的,在某种程度上,它为人工智能系统中的强化学习铺平了道路。
神经网络由模拟人脑工作方式的电子网络组成。每个网络都有一个输入和输出节点,以及由算法组成的中间隐藏层。输入节点被赋予初始数据集以执行一系列的操作,并且每次迭代都会创建一个数据字符串输出作为结果。然后,这个输出与实际结果数据集进行匹配,并将错误反馈给输入节点。这样一来,这个错误使得算法能够自行纠正,并越来越接近实际数据集。这个过程称为训练神经网络,每次迭代都会提高准确性。与 Boosting 算法执行迭代的方式相比,执行的迭代之间的关键区别在于,这里我们不必手动更新分类器,算法会根据错误反馈自行更改。
优缺点
这个过程的主要优点是它可以达到的准确度。该模型也是可重用的,因为它学习了实现准确性的方法,而不仅仅是为你提供直接的结果。这种方法的另一面是,模型可能会严重出错,并完全偏离不同的方向。这是因为归纳迭代有自己的过程,不需要人工监督。“Facebook 聊天机器人偏离了他们最初的目标,并用自己的语言在他们内部进行交流”就是一个很好的例子。但俗话说,聪明的东西有其自身的问题。如果我们想要创建更准确的模型和更智能的系统,我们必须准备好应对这一风险。
强化学习
强化学习是机器学习的一个有趣的案例,其中简单的神经网络被连接起来,它们与环境相互作用,从错误和奖励中学习。这里介绍的迭代以复杂的形式发生。迭代以奖励或惩罚的形式发生,分别对应得出正确或错误的结果。在每次这种交互之后,多层神经网络都会合并反馈,然后重新创建模型以提高准确性。典型的奖励和惩罚方法在某种程度上将其置于一个即不是受监督也不是不受监督的空间,但表现出两者的特征,并且还具有产生更准确结果的额外优势。这里的缺点是模型在设计上很复杂。多层神经网络在多次迭代的情况下很难处理,因为每一层可能对某种奖励或惩罚做出不同的反应。因此,它可能产生内部冲突,这些冲突可能导致系统停滞不前——无法决定下一步向哪个方向发展。
迭代的一些实际实现
许多现代机器学习平台和框架已经实现了自己的迭代过程,从而创建更好的数据模型,Apache Spark 和 MapReduce 就是两个这样的例子。两者实现迭代的方式在技术上是不同的,它们有其优点和局限性。
让我们来看看 MapReduce。它直接在磁盘上存在的 HDFS 文件系统上读取和写入数据。请注意,从磁盘读取和写入的每个迭代都需要大量的时间。这在某种程度上创建了一个更健壮和容错的系统,但在速度上妥协了。另一方面,Apache Spark 将数据存储在内存(弹性分布式数据集),比如 RAM 中。因此,每次迭代花费的时间要少得多,这使得 Spark 能够执行闪电般的快速数据处理。但是,Spark 执行迭代方式的主要问题是,动态内存或者 RAM 在存储迭代数据和执行复杂操作方面的可靠性远低于磁盘存储。因此,它的容错能力远低于 MapReduce。
将其整合在一起
为了总结讨论,我们可以大致如下来看一下迭代过程及其实现机器学习模型的阶段:
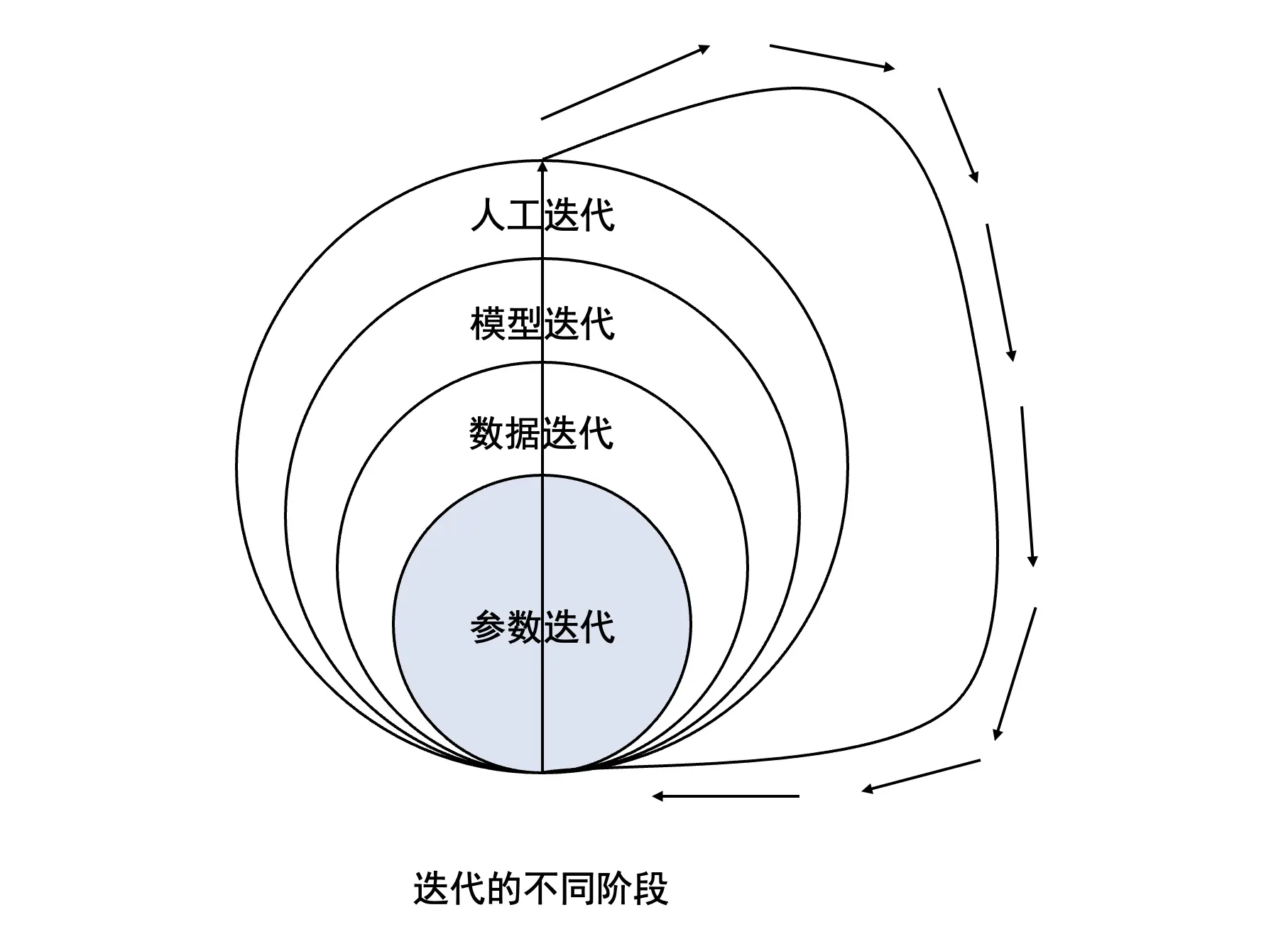
- 参数迭代:这是任何算法迭代的第一个也是固有的阶段。算法涉及到的参数运行多次,并在此过程中最终确定模型的最佳拟合参数。
- 数据迭代:一旦模型参数最终确定之后,将数据放入系统并模拟模型。将多组数据放入系统中,以检查参数在产生想要的结果方面的有效性。因此,如果数据迭代阶段表明某些参数不适合模型,则将它们带回参数迭代阶段,并添加或修改参数。
- 模型迭代:在初始参数和数据集最终确定后,进行模型测试/训练。模型测试阶段的迭代是关于使用相同的参数和数据集多次运行相同的模型模拟,然后检查错误量,如果错误在每次迭代中都有很大变化,则数据或参数或两者都有问题。对数据和参数进行迭代,直到模型达到准确性。
- 人工迭代:此步骤涉及到人工归纳的迭代,其中将不同的模型放在一起以创建功能齐全的智能系统。在这里,多层次的拟合和再拟合恰好可以实现一个连贯的总体目标,比如创建无人驾驶汽车系统或功能完全的人工智能(AI)。
迭代对于在不久的将来创建更智能的 AI 系统至关重要。对复杂数据集执行多次迭代的巨大内存需求继续带来重大挑战。但随着人工智能芯片、存储设备和数据传输技术的日益完善,这些挑战变得越来越容易应对。
我们相信,迭代机器学习技术将在不久的将来继续引领人工智能领域的转型。
由于本文是对英文博文的译文,本人对文章内容不享有版权。如有版权争议,可联系撤下本文。
As this article is a translation of an English blog post, I do not have the copyright of the content in this article. If there is a copyright dispute, please contact me to withdraw this article.
版权声明: 如无特别声明,本文版权归 仲儿的自留地 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 [译文]迭代机器学习:迈向模型准确性的一步 》
本文链接:https://lisz.me/ac/ml/iterative-learning.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!

Developer & Maintainer

