Kubernetes 基础平台的搭建
前言
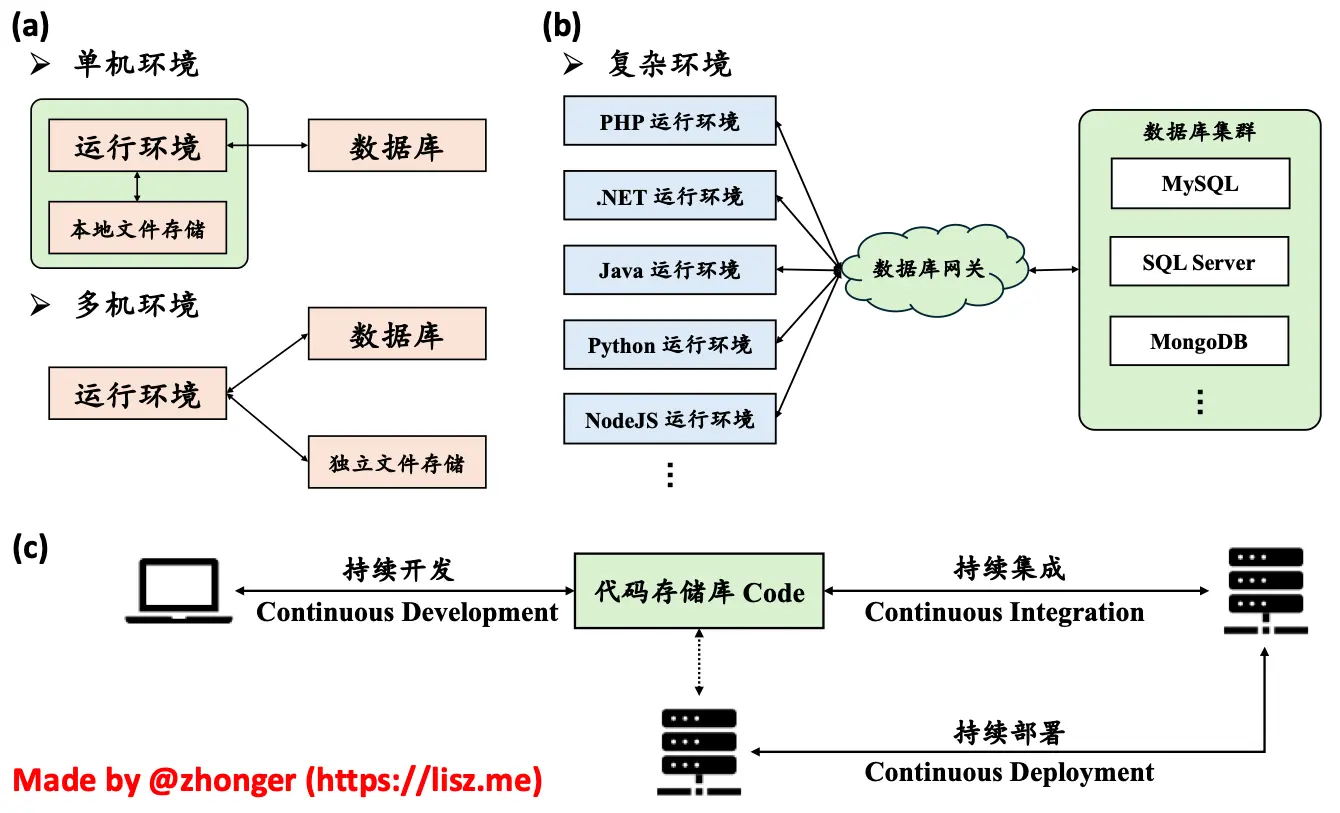
Web 应用的生产环境部署随着技术的发展不断地发生改变,如下图所示,从最早期的单机环境到多机环境,再发展到复杂环境:
- 单机环境指的是代码、运行环境、文件存储、数据库服务都在同一台服务器上的应用部署方式。通常来说,个人应用或者早期 Demo 应用大多采用这类方式。单机环境的优点在于不需要太多服务器资源,缺点在于过分依赖本地资源而没有高可用性、高可扩展性以及数据的安全保障。如果是云服务器作为单机环境,可以通过升级配置的方式来提高 CPU、内存和存储资源。至于数据则可以通过异机备份或本地备份的方式来保障数据的可靠性。
- 多机环境指的是同一应用所需的运行环境、数据库服务、文件存储服务分布在不同的节点或集群中的应用部署方式。这类方式的优点自然是具备高可用性、高可扩展性以及完备的数据安全保障,缺点则是需要大量的服务器资源。因此,多机环境通常是对外大量用户提供服务时常用的方式。
- 复杂环境打破了原有的瓶瓶罐罐,是多机环境的一种的超级形态。在复杂环境中,不再拘泥于服务器节点本身,而是利用 Web 应用将已有的云资源联系在一起。说得更直白一点,就是应用开发者不再需要关心应用运行环境、数据库服务、文件存储等基础环境的配置和管理,唯一需要关心的只有应用代码本身。这也是现在大部分 Web 应用的真实部署方式。
自从代码版本跟踪软件 Git 横空出世以来,逐步形成了以 Git 为中心的持续开发、持续集成和持续部署的现代应用开发方式。这与复杂环境的部署方式完全契合,由云服务提供商来提供和维护各类运行环境、数据库服务和文件存储,开发团队只需要专注于对代码存储库的管理。
举个例子,当某个开发成员完成了某个模块的开发并推送到某个分支,该分支创建后会自动触发持续集成进行自动 Review。自动 Review 通过后,开发团队负责人可以对该分支的代码更改进行审核,通过后允许将该分支与其他某个指定分支进行合并(合并操作也是通过持续集成自动进行)。当所有代码开发完毕后,由总负责人审核汇入最终部署的分支。审核通过后持续集成会自动合并代码并通过持续部署将完整的代码部署到真实的运行环境中。如今的 GitHub、GitLab 均能完成持续开发、持续集成和持续部署的全过程。当然,也有一些软件(比如 Jenkins 等)可以完成持续集成和持续部署两步,而持续开发则可以依托任意的 Git 托管服务。
以上叙述非专业解释,仅为个人看法,不喜勿喷。Kubernetes 官方将部署方式分为传统部署、虚拟化部署和容器部署三类。
实例解析
假设一个 Web 应用同时需要使用:
- 运行环境:PHP 运行环境、Python 运行环境、NodeJS 运行环境。
- 数据库服务:关系型数据库(比如 MySQL)、非关系型数据库(比如 MongoDB)、缓存数据库(比如 Redis)。
- 文件存储:用于存储用户头像、上传文件的对象存储(S3)、用于存储运行代码的文件存储(比如 NFS)。
- 高可用应用入口:比如 Nginx、HaProxy 等。
在单机环境中,按照以前我们碰见这种要求可能就要头大了,毕竟同时配置这么多环境难免会有不可预知的问题。不过现在,容器化技术(比如 Docker)可以帮助我们将所有的需求都拆分成独立的 container 实例。不但可以让它们之间在内部网络中互通,还可以对外只暴露必要的应用入口所需的 80 和 443 端口。这样一来,既将各项服务进行了合理拆分,又能保证应用服务的安全性。即使是需要对某个运行环境或者数据库服务进行版本升级,也可以很容易做到。
在多机环境中,我们如果还想用容器化技术,那就必须用容器化集群。很久以前,Docker 官方就提供了一种 Swarm 模式来组成容器化集群。这种方式的好处是非常简单配置、轻量易用,对于熟悉使用 Docker 的开发者来说只需要花很少的时间就能搞明白。缺点也很明显,Docker Swarm 依赖于 Docker API。也就是说,Docker 本身不支持的东西还是不支持,比如更加高效安全的网络、花式多样的存储等。为了能够更好跨主机集群地自动部署、扩展以及运行应用程序容器,我们选择使用 Kubernetes(缩写为 K8S)。
在 2014 年 Google 开源了 Kubenetes 项目,后来又贡献给了云原生计算基金会 CNCF。很多公司以 Kubernetes 为基础开发了自家的容器化集群平台,比如 RedHat 的 OpenShift,AWS 的 Elastic Kubenetes Services, EKS,Azure 的 Azure Kubernetes Services, AKS,阿里云的 Aliyun Container Service for Kubernetes, ACK,腾讯云的 Tencent Kubernetes Engine, TKE 等。
Kubernetes 架构
虽然 Kubernetes 官方文档已经将架构图以及相关概念介绍得非常清楚,但还是想说说自己的理解。类似于一般集群平台,K8S 也需要有至少一个控制节点(官方称之为“控制平面”)和一个工作节点。默认来说,K8S 不推荐控制节点同时作为工作节点,因为这会影响集群调度的可靠性和可用性。从下面的重绘架构图可以看出,K8S 集群会对外提供 API 以供用户从集群外进行调度。在集群内部,工作节点通过 kubelet 服务与控制节点直接连接,控制节点也通过 kubelet 服务向工作节点下达调度指令来管理工作节点上的 pod。
Pod 可以理解为 K8S 中应用的最小单位,一个 Pod 中可能会包括一个或多个 container (容器),这些容器间可以互通,但对外只有 Pod 有资格拥有 IP。这有点类似于进程与线程之间的关系,进程是拥有资源的最小单位,线程依赖于进程而存在,同一进程间的线程间可以无障碍通信,而不同进程间的通信则需要通过端口或 socket 来进行。
同一个工作节点上的 Pod 的 IP 属于同一个子网,不同工作节点的子网又属于同一个大子网 (podSubnet,一般需要在初始化集群时定义)。这样的设计在很大程度上减少了 IP 管理的难度,并且能够最大程度上减少容器暴露的风险。
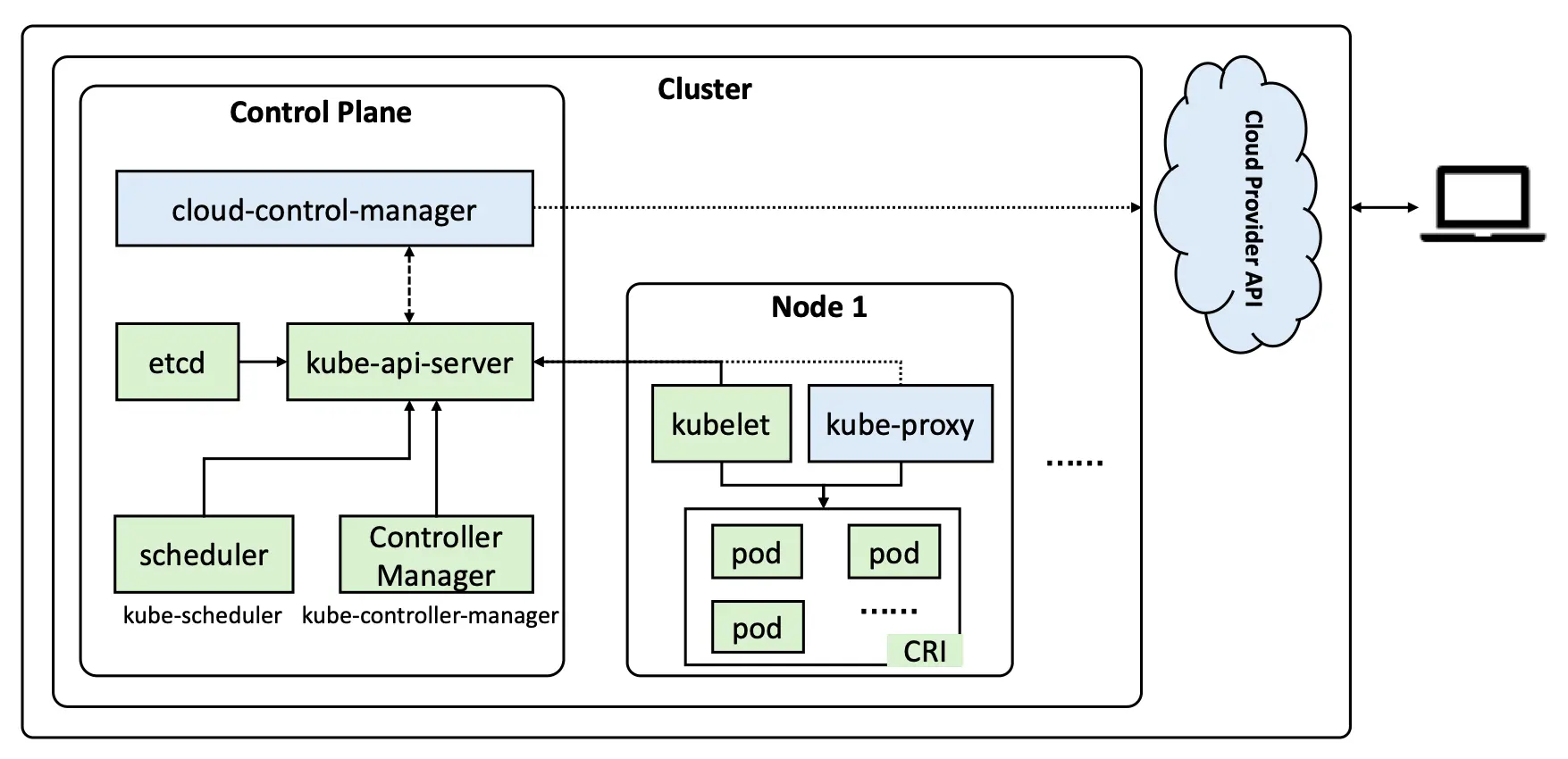
CRI,全名为 Container Runtime Interface(容器运行时接口),是 K8S 架构中 kubelet和容器运行时通信的主要协议。我们所熟知的 Docker 就是一种容器运行时,但是自从 K8S 1.20 版本弃用 Docker 自带的容器运行时接口 Dockershim 以来,我们只能使用额外的 CRI – cri-dockerd 来调用 Docker。因此推荐使用包含 CRI 的容器运行时 containerd 或者 cri-o 来替代 Docker。
组成部分
由于 K8S 是一款平台无关的容器集群方案,所以官方提供的方案只是一个整体,我们需要自行选择以下各项组件:
- 容器运行时 (CRI):如上所述,推荐使用 containerd 或者 cri-o 来替代 docker。下面实践部分将以 containerd 为例。
- 网络组件 (CNI, Container Network Interface):K8S 中网络有三种 Node、Pod、Service,其中 Node IP 是节点的 IP,用于连通或者暴露端口。Pod IP 是 Pod 的独立内网 IP,只能在 K8S 集群间访问。Service IP 是多个 Pod 共同组成 Service 后需要互通时使用的,一般仅在 Service 内部可访问,不能被用户访问。K8S 官方文档中 联网和网络策略 列举了很多可用的 CNI,这里我们选用 Calico 来进行实践。
- 服务发现 (DNS):默认为 CoreDNS,在配置完网络组件后自动创建,为 Pod 提供 DNS 解析服务,包括公网域名解析和 Service 别名解析。
- 容器存储接口 (CSI, Container Storage Interface):目前 K8S 基本上移除了大部分的第三方软件相关存储插件,转而通过第三方自行维护的 CSI 来扩充存储类的支持。可以通过查看 K8S 官网文档的 存储制备器 和 kubernetes-csi 的 Drivier 来了解更多。这里我们选用 NFS 的 CSI Driver 作为例子进行实践。
搭建 K8S 集群
在学习环境中,我们可以使用 kind、minikube 或者 kubeadm 在本地快速部署 K8S 集群;在生产环境中,我们可以使用 kops、Kubespray 或者 kubeadm 在多节点上快速部署 K8S 集群。所以这里我们采用了通用的 kubeadm 来搭建 K8S 集群。
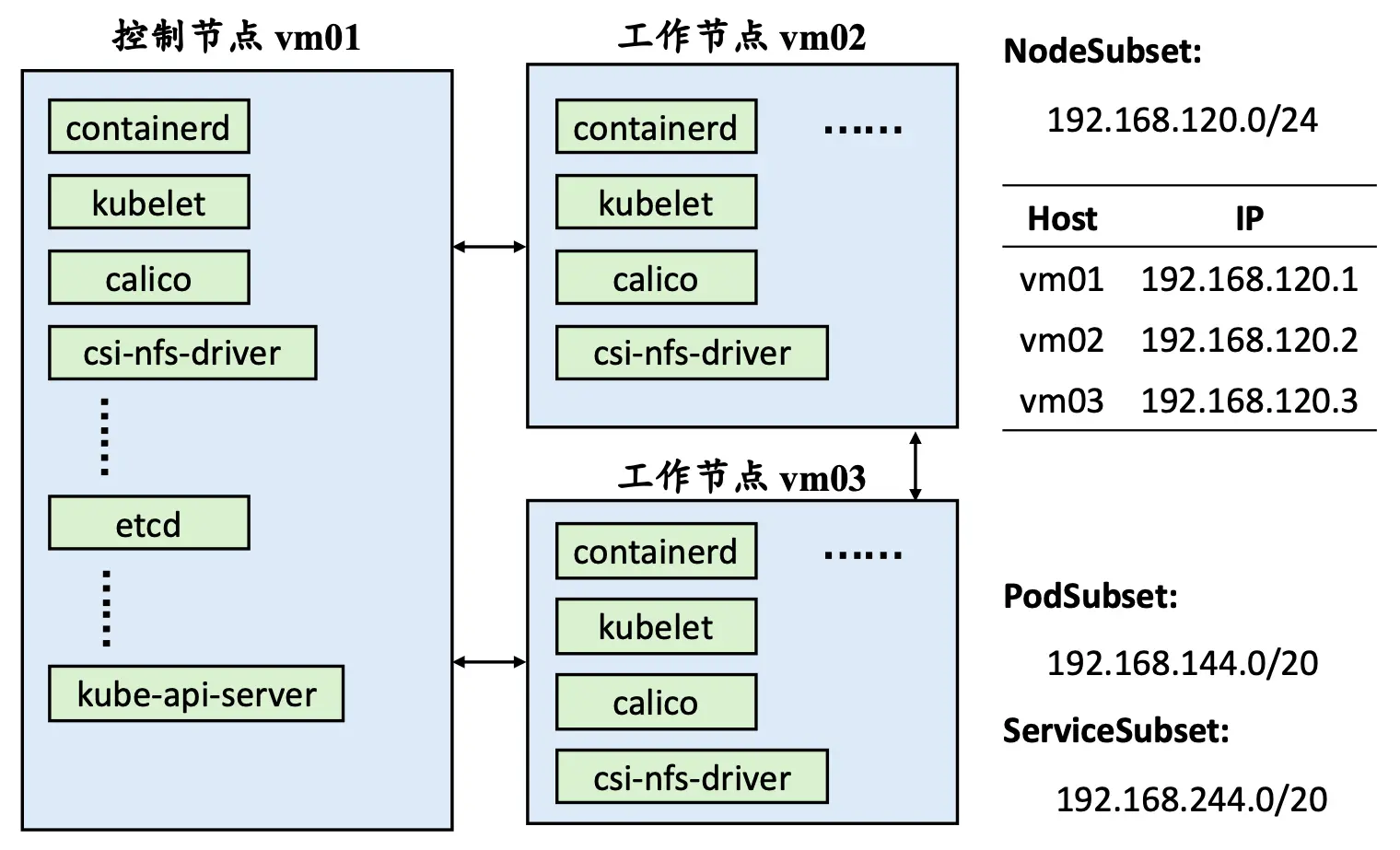
在正式部署之前需要规划实际架构、做一些基本准确以及安装必要的软件和工具 – kubelet,kubectl 和 kubeadm。下图为本实践规划的 NodeSubset、PodSubset 和 ServiceSubset。
基本准备
关闭 SWAP 交换分区
K8S 为了性能考虑默认必须关闭 SWAP 交换分区,而通常实体服务器安装后会有 SWAP 交换分区,云服务器或 VPS 没有。通过 sudo swapoff -a 命令可以临时关闭 SWAP 分区,或者通过注释 /etc/fstab 文件中的 swap.img 这一行并重启服务器永久关闭 SWAP 交换分区。
开启 IPv4 转发
由于 K8S 集群中同一个 Service 的 Pod 可能被分配到不同节点,那么不同节点间的 Pod 通信是非常必要的,即不同 PodSubnet 之间的通信需要通过 Node IP 来进行 IPv4 转发。执行以下命令添加允许 IPv4 转发到 /etc/sysctl.d/k8s.conf 文件里,并且立即生效:
# 添加配置
sudo tee -a /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
# 立即生效
sudo sysctl --system
配置主机名对应
K8S 集群初始化时会自动搜索主机名的 DNS 解析,目前测试的主机名没有完整的 FQDN 或 PTR 解析,因此有必要设置好主机名和 IP 对应信息到本地静态 DNS 解析文件 /etc/hosts 中。
# 分别在不同节点根据规划设置好主机名
sudo hostnamectl set-hostname vm01
sudo hostnamectl set-hostname vm02
sudo hostnamectl set-hostname vm03
# 修改所有节点的 /etc/hosts
sudo tee -a /etc/hosts << EOF
192.168.120.1 vm01
192.168.120.2 vm02
192.168.120.3 vm03
EOF
同步时间
K8S 集群的运行必须保证节点的时间是完全同步的,否则容易造成某些未知的 Bug。比如证书的过期时间将会被某些时间不同步的节点错误判断。推荐使用同一时区和同一 NTP 服务器,如下即可完成设置。
# 设置相同时区并查看
sudo timedatectl set-timezone Asia/Shanghai
timedatectl
timedatectl status
# 修改 NTP 服务器
sudo timedatectl set-ntp false
sudo sed -i 's/#NTP=/NTP=ntp.lisz.top/' /etc/systemd/timesyncd.conf
sudo sed -i 's/#FallbackNTP=ntp.ubuntu.com/FallbackNTP=ntp.aliyun.com/' /etc/systemd/timesyncd.conf
sudo timedatectl set-ntp true
# 重启服务使配置生效、同步时间并查看信息
sudo systemctl restart systemd-timesyncd
timedatectl show-timesync --all
date
安装必要软件和工具
安装 containerd
containerd 虽然是由 containerd 开发团队负责发布,但是 APT 或 YUM 镜像源仍然是由 Docker 官方负责,所以当我们添加 docker-ce 的镜像源后可以直接下载 containerd.io 来安装 containerd。当然, 我们可以从 containerd/containerd 直接下载二进制可执行文件。
# 添加镜像源
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/docker.gpg
sudo tee -a /etc/apt/sources.list.d/docker.list << EOF
deb [arch=amd64 signed-by=/etc/apt/trusted.gpg.d/docker.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/ $(lsb_release -c --short) stable
EOF
# 更新软件列表缓存并安装 containerd
sudo apt update && sudo apt upgrade -y && sudo apt install -y containerd.io
个人推荐使用 APT 或 YUM 方式安装 containerd。原因有二:一是国内有 docker-ce 镜像安装比较快,二是想要更新时非常容易。
配置 containerd
containerd 安装后默认没有配置文件也不会自动启动后台程序,所以需要准备配置文件并复制到 /etc/containerd/config.toml 再启动。由于 K8S 集群默认使用 registry.k8s.io 和 registry-1.docker.io 源下载容器镜像,为了提升速度建议切换到阿里云和 DaoCloud 的加速器。
containerd config default > containerd_config.toml
sed -i "s#registry.k8s.io#registry.cn-hangzhou.aliyuncs.com/google_containers#g" containerd_config.toml
sed -i "/containerd.runtimes.runc.options/a\ \ \ \ \ \ \ \ \ \ \ \ SystemdCgroup = true" containerd_config.toml
sed -i "s#https://registry-1.docker.io#https://docker.m.daocloud.io#g" containerd_config.toml
sudo mkdir -p /etc/containerd
cp containerd_config.toml /etc/containerd/config.toml
sudo systemctl daemon-reload
sudo systemctl enable containerd
sudo systemctl restart containerd
sudo systemctl status containerd.service && sudo ctr --version
由于 ctr 命令连接的 containerd 的 socket 文件只有 root 用户组有权限访问,所以目前只能使用 sudo ctr。如果想要直接使用 ctr 命令,可以使用 sudo usermod -aG root ubuntu 来将当前用户添加到 root 用户组。赋权之后需退出登录后再次登录才能生效。
安装 kubeadm 等
国内清华大学 TUNA 镜像源、阿里云镜像源等都提供了 kubeadm 等三件套工具的 APT 或 YUM 源,通过以下命令可以很容易完全安装。
由于 kubernetes 不同版本可能会存在较大差异,并且为了避免节点 kubernetes 版本在不自觉的时候升级造成兼容性问题,这里推荐固定 kubeadm 等三件套版本号,即不启用 apt upgrade 自动升级。管理员关闭 K8S 集群手动升级版本时不受影响。
# 添加镜像源
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/kubernetes/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
sudo tee -a /etc/apt/sources.list.d/kubernetes.list << EOF
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/kubernetes/core:/stable:/v1.30/deb/ /
# deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/kubernetes/addons:/cri-o:/stable:/v1.30/deb/ /
EOF
# 更新软件列表缓存并安装 kubeadm 三件套
sudo apt update && sudo apt install -y kubeadm kubelet kubectl
# 固定 kubeadm 等三件套版本
sudo apt-mark hold kubeadm
sudo apt-mark hold kubelet
sudo apt-mark hold kubectl
初始化集群
预下载镜像
在所有节点上使用以下命令提前下载好 K8S 集群所需的基本镜像,避免初始化时一直在等待各个节点下载镜像。
kubeadm config images list | sed -e 's/^/sudo ctr image pull /g' -e 's#registry.k8s.io#registry.cn-hangzhou.aliyuncs.com/google_containers#g' | sh -x
初始化控制节点
下载完所需的容器镜像后,在控制节点上使用 sudo kubeadm init --config=kubeadm_config.yaml 命令初始化控制节点。kubeadm_config.yaml 的内容如下所示:(建议将配置文件放置在 ~/k8s 目录下,cd ~/k8s 目录后执行初始化命令。)
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.120.1
bindPort: 6443
nodeRegistration:
criSocket: "unix:///run/containerd/containerd.sock"
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: stable
imageRepository: "registry.cn-hangzhou.aliyuncs.com/google_containers"
networking:
podSubnet: 192.168.144.0/20
serviceSubnet: 192.168.244.0/24
如果没有配置主机名对应的话,这里初始化会一直卡在 API Health 检测的步骤,实际上是因为没有主机名和 IP 对应而无法启动 API Server。
kubeadm 初始化成功后需要复制验证文件才能在控制节点管理 K8S 集群,如下所示:
# 复制验证文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 查询节点状态
kubectl get nodes -o wide
工作节点加入集群
刚才初始化集群后会出现工作节点加入集群的命令,形如:
kubeadm join 192.168.120.1:6443 --token z9sdsdi.tdeu74psxqi8rhdt \
--discovery-token-ca-cert-hash sha256:87c4f8dd9dabaf2e5e793c0404c74dd8f9f56153000dad3c1a3238a3e8b0beff
注意这里需要加上 sudo 之后再在工作节点上执行加入集群操作。加入完成后可以在控制节点上使用 kubectl get nodes -o wide 查看是否有了刚加入的工作节点的信息。由于目前还没有配置网络组件,除了控制节点外,其他工作节点应该均为 NotReady 状态。如果使用 kubectl get pods --all-namespaces 命令查看所有启动的 Pod,应该看到除两个 CordDNS 的 Pod (比如 0/1) 以外的所有 Pod 的状态都是完成启动 (比如 1/1)。
工作节点加入后可以配置不同的标签,比如如下是配置为工作节点和添加 gputype 字段标签:
kubectl label node vm02 node-role.kubernetes.io/worker=
kubectl label node vm03 node-role.kubernetes.io/worker=
kubectl label node vm02 gputype=P100
kubectl label node vm03 gputype=A100
添加组件
配置 Calico 网络
Calico 支持一套灵活的网络选项,可以根据情况选择最有效的选项,包括非覆盖和覆盖网络,带或不带 BGP。Calico 使用相同的引擎为主机、Pod 和应用程序在服务网格层执行网络策略。如下所示可以很简单地为 K8S 集群启用 Calico 网络:
- 创建 Calico 所需的 operator(需要镜像
quay.io/tigera/operator:v1.34.5,可提前下载),仅在控制节点创建 Pod; - 创建和初始化 K8S 集群时对应的网络规划,主要是 PodSubset 配置,如下面修改过的 yaml 配置文件。这里为了加速创建过程,还添加了
registry字段来使用 DaoCloud 加速器。
mkdir -p ~/k8s/calico & cd ~/k8s/calico
wget -c https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/tigera-operator.yaml
wget -c https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/custom-resources.yaml
kubectl create -f tigera-operator.yaml
kubectl create -f custom-resources.yaml
# This section includes base Calico installation configuration.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.Installation
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
ipPools:
- name: default-ipv4-ippool
blockSize: 26
cidr: 192.168.144.0/20
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
registry: m.daocloud.io
---
# This section configures the Calico API server.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
如果通过 kubectl get pod --all-namespaces 发现哪个相关 Pod 卡在了拉取镜像的步骤,可以手动镜像。一般来说,使用修改的 DaoCloud 加速器下载应该没什么太大问题。创建 Calico 网络完成后会多出来 3 个命名空间: tigera-operator、 calico-system 和 calico-apiserver。新增的 Pod 应该如下所示:
| 节点主机名 | 新增 Pod | 备注 |
|---|---|---|
| vm01 | tigera-operator | Calico 网络所需的描述子 |
| vm01 | calico-kube-controller | Calico 网络控制器 |
| vm01 | calico-apiserver | Calico 网络 API,一般有两个 Pod |
| vm01 | calico-typha | 优化和减少 Calico 对 K8S API 服务器的负载 |
| vm01 | calico-node | Calico 网络节点客户端 |
| vm01 | csi-node-driver | CSI 驱动 |
| vm02 | calico-typha | 优化和减少 Calico 对 K8S API 服务器的负载 |
| vm02 | calico-node | Calico 网络节点客户端 |
| vm02 | csi-node-driver | CSI 驱动 |
| vm03 | calico-node | Calico 网络节点客户端 |
| vm03 | csi-node-driver | CSI 驱动 |
配置 NFS CSI 驱动和存储类
NFS CSI 驱动由 kubernetes-csi/csi-driver-nfs 项目提供支持。不过在正式安装驱动之前需要先安装 NFS 客户端,否则 NFS CSI 驱动也无法正常启用。为了加速下载容器镜像,这里推荐将配置中的 registry.k8s.io 源切换到 k8s.m.daocloud.io 加速器。
# 在所有节点安装 NFS 客户端支持
sudo apt install -y nfs-common
# 下载 NFS CSI Driver 配置文件
mkdir -p ~/k8s/csi && cd ~/k8s/csi
git clone https://github.com/kubernetes-csi/csi-driver-nfs.git
# 修改容器镜像为 DaoCloud 加速器
cd csi-driver-nfs/deploy/v4.9.0
sed -i "s/registry.k8s.io/k8s.m.daocloud.io/" ./*
# 返回上上层目录,并安装 NFS CSI 驱动
cd ../../
./deploy/install-driver.sh v4.9.0 local
安装 NFS CSI 驱动后会在 kube-system 命名空间中多出四个 Pod,其中一个 Pod 为 csi-nfs-controller,其他每个节点一个 csi-nfs-node 的 Pod。然后需要使用 kubectl apply -f nfs.yaml 命令创建一个 NFS 的存储类用于提供给应用程序,配置文件 nfs.yaml 内容如下所示:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: nfs.csi.k8s.io
parameters:
server: nfs_server_ip
share: /home/data
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
mountOptions:
- async
- rsize=32768
- wsize=32768
- nconnect=8
- nfsvers=4.1
- hard
# 查看新增的存储类
╰─$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-csi (default) nfs.csi.k8s.io Retain Immediate true 4d1h
GPU 支持
K8S 的 GPU 支持是由 NVIDIA 提供的,需要工作节点先安装 NVIDIA 驱动和容器驱动,再在控制节点上部署 nvidia-device 插件支持。
# 查看可安装 NVIDIA 驱动
╰─$ ubuntu-drivers devices
modalias : pci:v000010DEd000026BAsv000010DEsd00001957bc03sc02i00
vendor : NVIDIA Corporation
driver : nvidia-driver-550-open - distro non-free
driver : nvidia-driver-550 - distro non-free recommended
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-535-server-open - distro non-free
driver : nvidia-driver-535-open - distro non-free
driver : nvidia-driver-535 - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
# 安装 NVIDIA 驱动,并重启生效
sudo apt install -y nvidia-driver-535
sudo apt-mark hold nvidia-driver-535
# 添加 NVIDIA Container Toolkit 源
curl -fsSL https://mirrors.ustc.edu.cn/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 更新软件列表缓存,安装 nvidia-container-toolkit
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
# 为 containerd 容器运行时增加 NVIDIA 选项
sudo nvidia-ctk runtime configure --runtime=containerd
# 修改 /etc/containerd/config.toml 配置文件中默认运行时为 NVIDIA
# 原来的默认运行时是 runc
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
# 重新加载 containerd 配置文件并重启服务生效
sudo systemctl daemon-reload
sudo systemctl restart containerd
# 在控制节点为 K8S 集群创建 NVIDIA device 插件支持
cd ~/k8s
wget -c https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.16.2/deployments/static/nvidia-device-plugin.yml
sed -i "s/nvcr.io/nvcr.m.daocloud.io/" nvidia-device-plugin.yml
kubectl create -f nvidia-device-plugin.yml
# 验证 GPU 是否被 K8S 识别
kubectl describe node vm02 | grep nvidia.com/gpu:
NVIDIA GPU 驱动和容器驱动只需在有 NVIDIA GPU 的工作节点上配置,并且一定要修改默认运行时为 NVIDIA,否则无法被 K8S 识别。NVIDIA device 插件支持在控制节点上提交安装请求但会在每一个工作节点上安装,即使没有 NVIDIA GPU 存在。
可能遇到的问题和解答
这种情况下需要为 kubelet 和 containerd 的 service 设置代理。kubelet 的配置文件为 /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf,containerd 的配置文件为 /usr/lib/systemd/system/containerd.service。配置内容如下所示。配置完后需要使用 sudo systemctl daemon-reload 来应用配置更改,并且使用 sudo systemctl restart kubelet 和 sudo systemctl restart containerd 重启服务。
# sudo vim /usr/lib/systemd/system/containerd.service
# sudo vim /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
[Service]
...
Environment="HTTP_PROXY=http://proxy.ip:3128"
Environment="HTTPS_PROXY=http://proxy.ip:3128"
Environment="NO_PROXY=localhost,127.0.0.1"
结语
K8S 集群的搭建并非一件十分复杂的事情,比较复杂的是根据实际的需求和自己对于 K8S 的理解来搭建出更合适的 K8S 集群。虽然 K8S 集群已经逐步开始取代一般的 Docker 单机应用服务部署方案,但是就个人实际的应用规模或者应用本身而言,K8S 集群本身的维护和调整的代价要远高于 Docker 单机应用服务部署。如果是有高可用性、高可靠性等的需求,那么 K8S 可能是目前最好的需求。
正如在前言中所述,有了 K8S 持续开发、持续集成和持续部署成为了现实,开发者可以把更多的注意力都放在应用代码开发。同时,类似于 JupyterHub 这类会有动态扩展和分配资源需求的应用,最佳的部署方式可能就是 K8S 了。当然,听说现在的大模型 ChatGPT 等也都是在 K8S 上训练出来的。
K8S 的确是大有可为!
参考资料
- Continuous Development
- AWS – 什么是持续集成?
- IBM – What is continuous deployment?
- Docker Swarm vs Kubernetes: how to choose a container orchestration tool
- 维基百科 – Kubernetes
- IBM – 第5回 『Red Hat OpenShift と Kubernetes の違い』
- Kubernetes 文档 - 概念 - Kubernetes 架构
- 基于 Containerd 运行时搭建 Kubernetes 集群实践
版权声明: 如无特别声明,本文版权归 仲儿的自留地 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 Kubernetes 不完全入门 》
本文链接:https://lisz.me/tech/k8s/k8s-introduction.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!

Developer & Maintainer
